Improve resilience with fallbacks
Introduction
Production AI traffic is not nearly as reliable as it looks on a calm afternoon. The major commercial providers run high-availability infrastructure, but they still have bad hours: regional incidents, capacity exhaustion, rate-limit throttling, model deprecations rolled out faster than expected, and the occasional outright outage. An application that calls a single provider directly has no answer to any of these events; the user sees an error, and someone is paged. The platform's fallback model removes that single point of failure without requiring any retry or branching logic inside the application. A fallback policy is an ordered list of backends. The gateway tries the first one; if the call fails with a recoverable error, the gateway walks to the next backend in the list and tries again, continuing until either a backend succeeds or the chain is exhausted. The calling application sees a single request that either returns a response or returns a final error; the underlying failover happens inside the gateway and is invisible to the caller. This guide covers how to design that chain, configure it against an existing API key, exercise the failover path to confirm it behaves as expected, and verify in Request Logs which backend actually served each request.
Persona: Developer working in the Agent Router Console.
Estimated time: 10--20 minutes, plus a short period of intentional failure exercise.
When this guide applies
Fallback chains are the right tool when the goal is resilience: keeping requests successful in the face of provider issues, without distributing traffic deliberately across providers under normal conditions. The chain is walked only on failure; a healthy primary provider serves 100 % of traffic, and the secondary backends are effectively idle until something goes wrong.
For other routing intents, different patterns apply:
| Intent | Pattern | Where it is covered |
|---|---|---|
| Distribute traffic by weight (cost, evaluation, gradual rollout) | Traffic splitting | Reduce Cost with Traffic Splitting |
| Route based on request attributes (tenant, header, task type) | Advanced routing rules | Apply Advanced Routing Rules |
| Enforce data residency or compliance boundaries | Fallback policy with carefully chosen providers | This guide (see Routing under compliance constraints below) |
Fallback and traffic splitting can be combined. A weighted split selects the primary backend for a given request, and an additional fallback chain takes over only when the chosen backend fails. The patterns are not mutually exclusive.
Outcomes
By the end of this guide:
- A fallback policy with at least two backends from different providers is attached to a working API key.
- The chain has been tested under at least one simulated failure, with the gateway falling through to the secondary backend.
- Request Logs show, for each request, which backend actually handled it and whether a fallback event occurred.
Prerequisites
This guide builds directly on Route Requests Across Providers. Specifically, the following should already be in place:
- An API key created in the Console, with a working routing configuration attached.
- At least two enabled models in the Admin Dashboard, ideally from different upstream providers. A chain with two backends from the same provider still works mechanically, but it provides no protection against a provider-wide outage, which is the most common failure the chain is designed to absorb.
- A terminal with
curl(or a Python environment with theopenaipackage) for the exercise step.
Step 1: choose the chain composition
A good fallback chain is not "a primary model plus whatever else is enabled". The composition of the chain determines what kinds of failures it can absorb and how surprised the calling application will be when failover occurs.
Three considerations matter when choosing backends:
- Provider independence. The chain protects against provider failures only to the extent that its backends fail independently. A chain consisting of two OpenAI models still goes down when OpenAI does. A chain that alternates providers (for example, an OpenAI primary with an Anthropic or Google secondary) absorbs single-provider outages without disruption.
- Quality consistency. When the chain falls through, the application gets a response from a different model. If the secondary model produces meaningfully worse output, the failover is visible to the end user even though the request technically succeeded. Where quality consistency matters, choose secondaries that are close to the primary in capability: frontier model behind frontier model, not frontier model behind a budget option.
- Cost profile. Some chains are deliberately built so that the secondary is cheaper than the primary. This is acceptable when degraded-but-cheaper output is preferable to no output at all, and it has the side effect of reducing cost exposure during long-running incidents on the primary provider.
A typical first chain pairs a primary frontier model with one secondary from a different provider:
| Position | Example backend | Role |
|---|---|---|
| Priority 0 (Primary) | gpt-4o | Serves 100 % of traffic under normal conditions |
| Priority 1 (Fallback) | claude-sonnet-4-20250514 | Used when the primary returns a recoverable failure |
Additional backends can be added at priority 2 and beyond. The marginal value drops quickly (two well-chosen backends absorb the vast majority of realistic incidents), but a third backstop is reasonable for workloads with strict SLA commitments.
Step 2: configure the fallback policy
The chain is attached to the API key created in the previous guide. The same key can hold only one routing configuration at a time, so editing this configuration replaces whatever was attached previously.
- From the API Keys page in the Console, open the detail page of the key the configuration should apply to.
- Scroll to the Routing Configuration section.
- Click Configure or Add Rule.
- Select Fallback Policy.
- Add the primary model and select it at priority 0.
- Click Add Fallback and choose the secondary backend. The Console assigns priority 1 automatically.
- Optionally repeat to add further backups at priorities 2 and beyond.
- Save the configuration and confirm the Active toggle is on.
The Console exposes drag-and-drop reordering and a remove control on each row, which is useful when chains are being tuned over time, for example when a secondary provider is being promoted to primary after performing well during an incident.
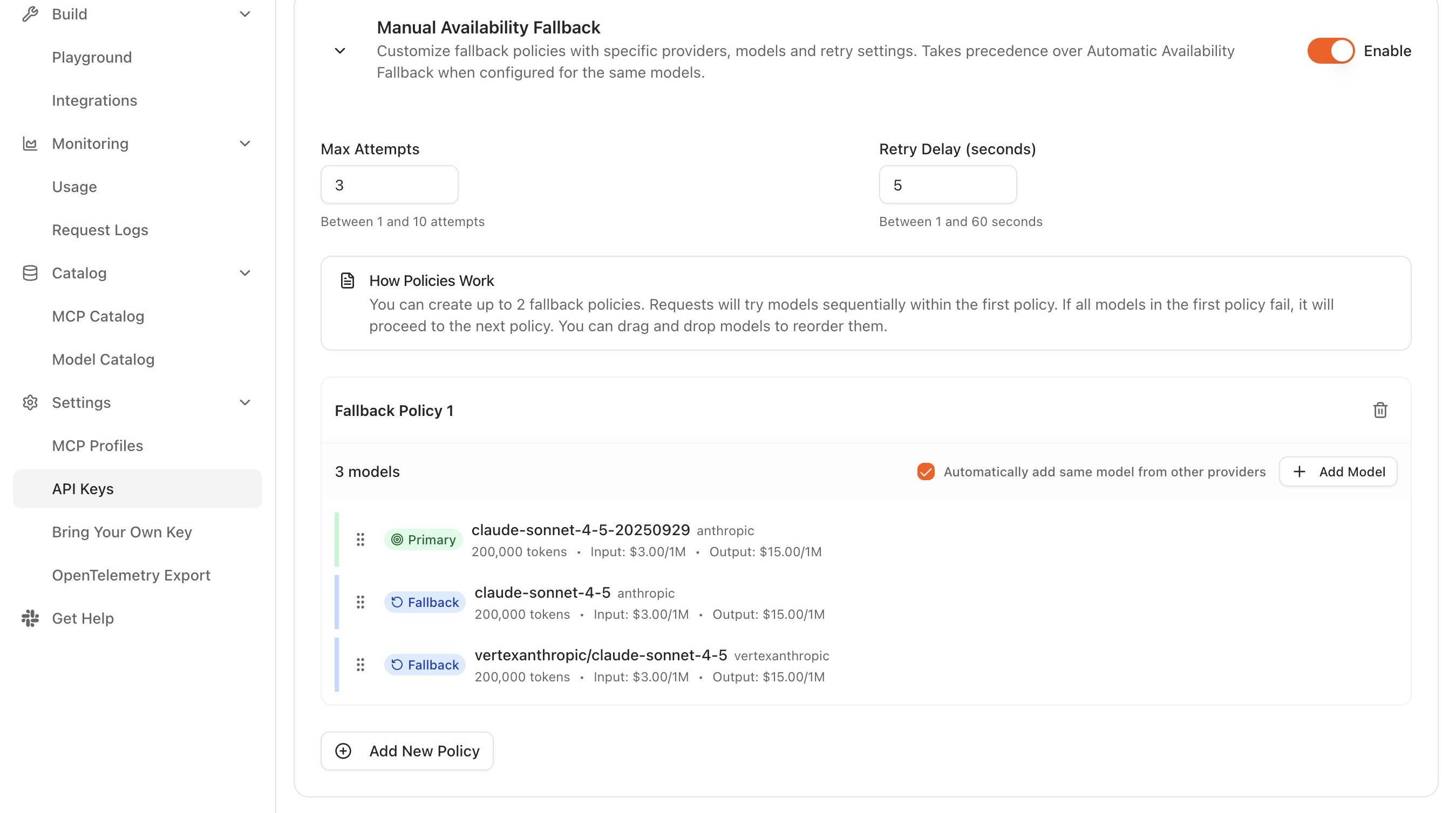
Fallback policy field reference
The Routing Configuration section exposes the following controls for a fallback policy:
- Priority. Each backend is assigned a priority level that fixes its position in the chain. Priority 0 is the primary and receives all traffic under normal conditions; priority 1 is the first fallback, priority 2 the second, and so on. The error from the last attempted backend is returned to the caller only when every backend in the chain has failed.
- Weight. Each backend in a fallback chain is assigned a weight of 1, so a single backend handles all traffic at its priority level. Weight is the mechanism used by traffic splitting rather than fallback; in a fallback policy it stays fixed at 1.
- Active/inactive toggle. A policy can be switched inactive without being deleted. While inactive, the chain is not enforced and requests go directly to the model named in the API call.
- Reorder. Drag a row, or use the priority controls, to change a backend's position in the chain, then save.
- Remove. The remove control on a row drops that backend; the remaining backends keep their relative priority order.
Keep one API key per logical chain composition rather than swapping the configuration on a shared key. Per-key routing is the platform's natural separation boundary, and Request Logs are filtered per key, so a separate key per chain keeps the analytics tidy and the rollback path obvious.
Step 3: test the failover path
A fallback chain that has never failed over is effectively unverified. The simplest way to exercise the chain is to introduce a failure on the primary backend and observe whether the gateway successfully walks to the secondary. Two approaches are practical, depending on how much disruption is acceptable in the environment under test.
- Misconfigure the primary temporarily. Change the primary backend in the routing configuration to a model that is enabled in the catalogue but lacks a working provider connection, then send a request. The gateway records the primary failure and falls through to the secondary, which should succeed. Restore the original primary after the test.
- Use a non-production API key. Repeat the exercise against a key that is not serving production traffic, so that the experiment is fully isolated from real users.
Send a test request after each change:
curl https://YOUR_GATEWAY_URL/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": [{"role": "user", "content": "Confirm which backend served this request."}]
}'
The request should still succeed. The model field in the response body reflects the backend that actually produced the answer, which, during a deliberate failover exercise, should be the secondary rather than the primary.
Not every provider failure is a recoverable one. The gateway walks the chain on transient errors (5xx responses, timeouts, connection failures, or rate-limit responses) but not on client-side errors such as malformed requests or authentication failures. Those are returned to the caller directly, because retrying them against a different backend would not change the outcome.
Step 4: verify the failover in request logs
The exercise above is only useful if its result is observable after the fact. Request Logs records, per request, which backend actually served the response and whether a fallback event occurred.
- In the Console, open Monitoring → Request Logs.
- Filter by the API key used in the test.
- Locate the request issued during the exercise.
- Expand the row to see the detail panel.
- Confirm the Resolved model field matches the secondary backend, not the primary. If a fallback event is recorded, it appears in the request timeline as a separate attempted-and-failed entry on the primary, followed by a successful entry on the secondary.
The expected pattern in normal operation is the opposite: every request resolves to the primary, and no fallback events appear. A sudden cluster of fallback events in production is a strong leading indicator that something is happening on the primary provider's side, often visible in Request Logs before the provider's own status page acknowledges the incident.
For richer filtering (by time range, by status, or by resolved model), see Monitor traffic and usage.
Routing under compliance constraints
Fallback chains are also the natural mechanism for policy-driven routing where compliance rather than resilience is the dominant concern. Because the chain contains only the backends explicitly added to it, the chain itself is the enforceable boundary: a chain that contains only EU-hosted providers cannot, by construction, route to a US-hosted provider, regardless of what the calling application requests.
Three common patterns use this property directly:
- Data residency. Build the chain from providers in the required region only (for example, Azure EU as the primary with GCP EU as the secondary) so failover never leaves the region.
- Approved providers. Limit the chain to providers that have been reviewed and approved for the use case in question, and assign that chain to a key dedicated to that use case.
- Output consistency. Use the same logical model class across positions in the chain to keep response quality steady during failover, even when the upstream provider changes.
There is no "compliance mode" to enable. The boundary is enforced by the composition of the chain itself.
What to do next
- Reduce cost with traffic splitting: distribute traffic across backends by weight rather than priority, useful for cost management and gradual rollout.
- Apply advanced routing rules: combine fallback semantics with attribute-based dispatch.
- Use your own provider credentials: introduce BYOK credentials into one or more positions in the fallback chain.
- Monitor traffic and usage: extend the verification step into ongoing dashboards, with cost and latency tracked per resolved model.
The guide assumes the fallback chain configured above remains attached to the key. Subsequent guides build on this configuration rather than replacing it.
Where to go next